nono’s security model is built on a single premise: the sandboxed process is untrusted. Every architectural decision follows from this. The sandbox must be enforced by the kernel, must be irreversible once applied, and must not depend on the cooperation of the sandboxed process.
This page explains the layered enforcement architecture, the trust boundaries between components, and why specific mechanisms were chosen.
Trust Boundaries
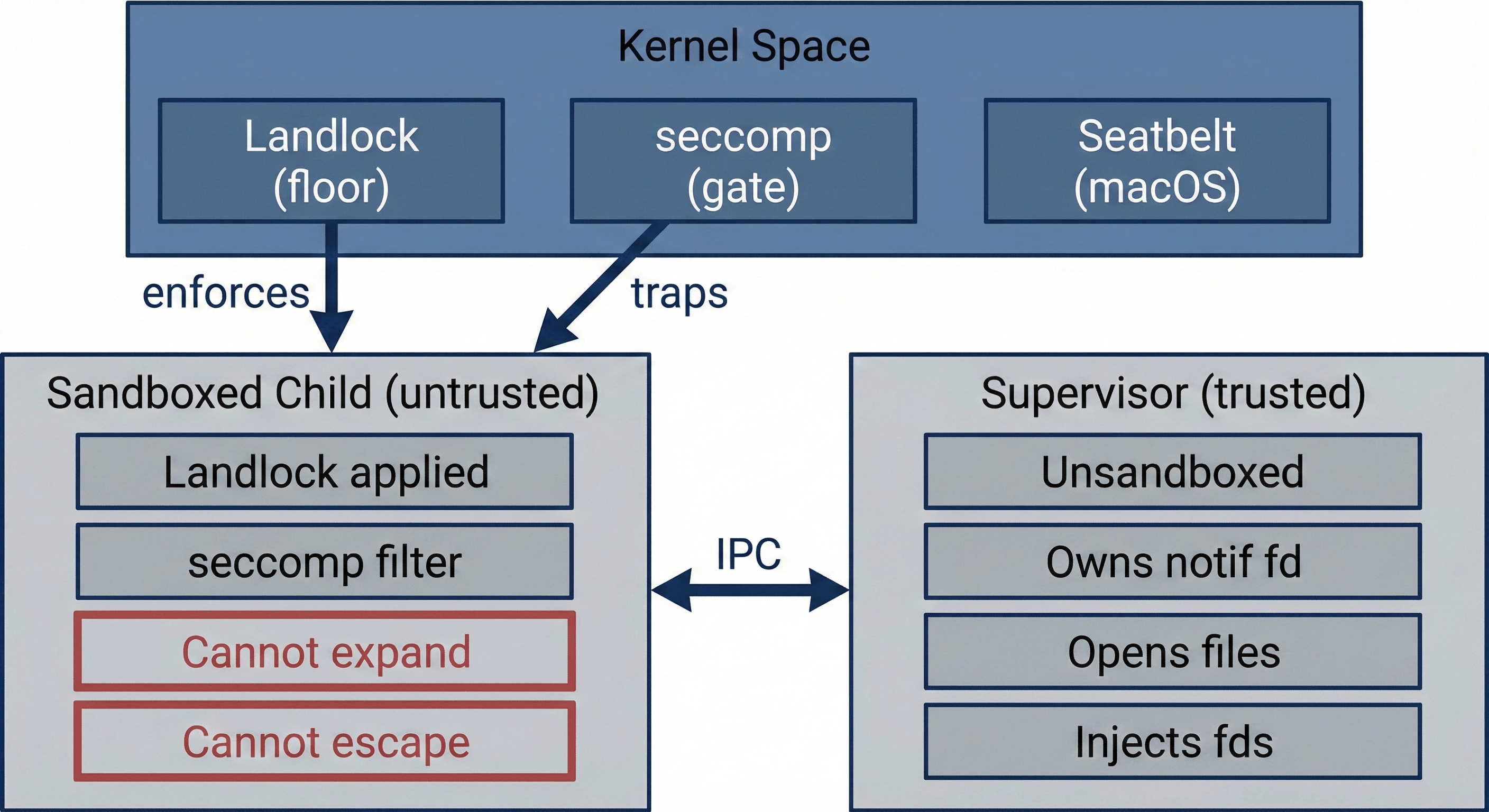 There are three trust domains:
There are three trust domains:
| Domain | Trust Level | Role |
|---|
| Kernel | Fully trusted | Enforces Landlock rules, delivers seccomp notifications, blocks unauthorized syscalls |
| Supervisor (parent) | Trusted | Records audit events, receives trapped syscalls, consults approval backend, opens files, injects file descriptors |
| Sandboxed child | Untrusted | Runs the agent command under full kernel enforcement |
| Domain | Trust Level | Role |
|---|
| Network proxy | Trusted (runs in supervisor) | Filters outbound connections by host, injects credentials, enforces deny CIDRs |
localhost:<port> — all other outbound TCP is blocked at the kernel level. A session token (256-bit random) prevents other localhost processes from using the proxy.
Attach and Detach Security Model
A natural question is: if the child is structurally sandboxed, how can nono attach reconnect to its terminal later?
The answer is that attach does not connect to the sandboxed child directly.
The PTY architecture is:
- The sandboxed child runs on the slave side of a PTY
- The trusted supervisor owns the master side of that PTY
nono attach connects to a local Unix socket exposed by the supervisor- The supervisor relays terminal I/O between the attached client and the PTY master
So the attach path stays entirely inside the already-trusted supervisor boundary. The sandboxed child never gains a new capability just because a human attaches to watch or interact with it.
What attach does not do
- It does not disable or relax the kernel sandbox
- It does not give the child new filesystem or network rights
- It does not create a backchannel from the child to arbitrary host terminals
- It does not bypass supervisor mediation or protected-root checks
Attach is a terminal transport, not a capability expansion mechanism.
Why this does not weaken the sandbox boundary
In supervised mode, the supervisor is already part of the trusted computing base. It already:
- owns the seccomp-notify fd
- mediates approvals
- may run rollback snapshots
- records audit events and session metadata
- may compute audit-log integrity metadata
- may run the network proxy
- manages the session registry and PTY
The attach socket does not introduce a new trust domain. It is another supervisor-owned interface inside that same trusted boundary.
The important distinction is:
- sandbox boundary: kernel-enforced restrictions on the child
- attach boundary: who is allowed to connect to the supervisor’s PTY relay
These are separate concerns. Attach affects terminal access to the session, but it does not alter the kernel sandbox applied to the child.
Local authentication model
Current attach is local-only and same-user only.
The supervisor protects attach with:
- a private session registry directory
- owner-only attach socket permissions
- kernel peer-credential checks on accepted Unix socket peers
This is strong enough for the current local runtime model:
- another local user should not be able to attach
- a peer with the wrong uid is rejected before terminal replay or client attach proceeds
This is not a remote authentication protocol. It does not distinguish between two processes running as the same uid, and it is not intended to support cross-host attach. Future HTTP or remote attach will support a much stronger authentication and authorization layer.
nono’s trust boundary is agent containment — restricting what the sandboxed child can access — not guest/host isolation between same-user processes. If an attacker has arbitrary code execution as your user, they already own all your processes and files; the attach socket does not expand their capabilities. If you need stronger isolation between same-user processes — for example, in a multi-tenant hosting environment — run nono inside a container or microVM. That adds a guest/host boundary that nono does not provide on its own.
Session JSON files in $XDG_STATE_HOME/nono/sessions/ (default ~/.local/state/nono/sessions/) contain supervisor and child PIDs, the command line, profile name, working directory, and network mode. These files are protected by directory permissions (0o700) and file permissions (0o600), but are readable by any process running as the same user.
nono applies best-effort redaction before persisting command arguments in session metadata, audit records, rollback metadata, and audit attestations. It scrubs common secret-bearing forms such as --token VALUE, --api-key=VALUE, sensitive HTTP headers, URL userinfo, and sensitive query parameters.
The default redaction policy can be extended in ~/.config/nono/config.toml with [redaction].extra_flags, [redaction].extra_headers, and [redaction].extra_query_keys. Removing a built-in default is treated as unsafe debugging behavior: [redaction].allow_unredacted_defaults is rejected unless [redaction].unsafe_redaction_overrides = true is also set. When a session uses a non-default redaction policy, audit events and audit attestations include a redaction-policy diff.
This is a safety net, not a secret-management boundary. Avoid passing secrets as CLI arguments — use keystore-backed credential injection or proxy credential injection instead.
The Two-Layer Architecture
Layer 1: Landlock (the floor)
Landlock LSM provides the hard security floor. Once restrict_self() is called, the child process is permanently restricted to its initial capability set. No API exists to expand or remove the restrictions. Child processes inherit them. The only escape is a kernel exploit.
Landlock is:
- Unprivileged — any process can sandbox itself without
CAP_SYS_ADMIN or root
- Irreversible — the kernel provides no undo mechanism
- Inherited — all child processes and threads inherit the ruleset
- Available — present on any kernel 5.13+ (Ubuntu 22.04+, Fedora 35+, Debian 12+)
This layer alone provides a complete sandbox. A process restricted by Landlock cannot access paths outside its allowed set, period. The second layer exists to make the sandbox more usable, not more secure.
Layer 2: seccomp-notify (the gate)
seccomp user notification (SECCOMP_RET_USER_NOTIF) provides dynamic capability expansion on top of the Landlock floor. A BPF filter traps openat and openat2 syscalls before they reach Landlock and routes them to the supervisor for a decision.
The critical property: seccomp runs before Landlock. When the child calls open(), the seccomp filter fires first, suspending the syscall and notifying the supervisor. The supervisor can then:
- Deny — return
EPERM to the child (the syscall never reaches Landlock)
- Approve — open the file itself and inject the fd into the child via
SECCOMP_IOCTL_NOTIF_ADDFD
On approval, the child’s open() call returns a valid file descriptor. The child never executes its own openat — the supervisor’s open() is the single point of truth. The agent does not need to know nono exists; its standard file operations succeed after a brief pause during approval.
Why This Ordering Matters
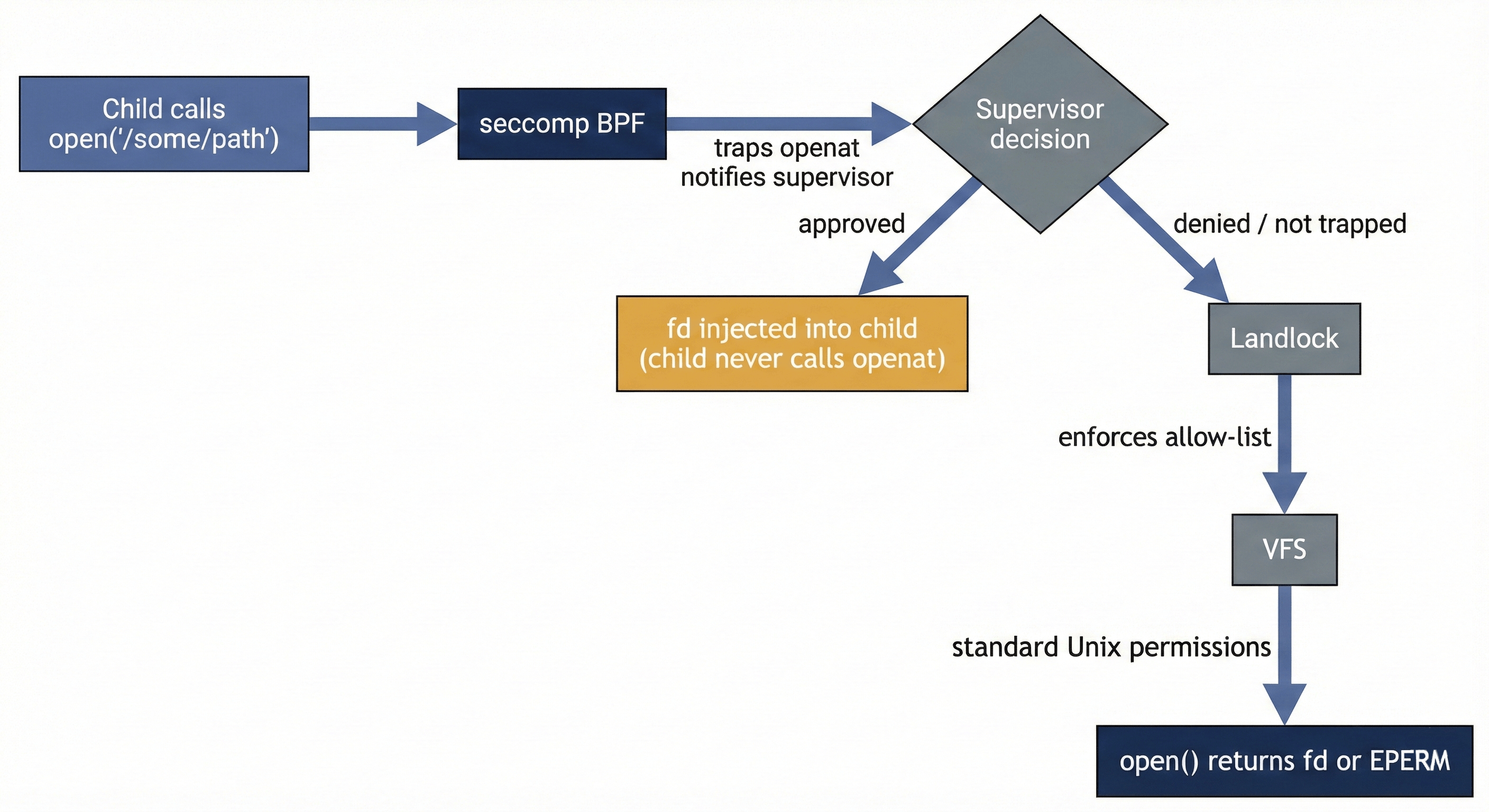 If the supervisor has a bug and fails to inject an fd, the child’s syscall falls through to Landlock, which denies it. The Landlock floor catches supervisor failures. This is defense in depth: the dynamic layer can only grant access within what the supervisor can open; the static layer ensures the child never exceeds its baseline even if the dynamic layer breaks.
If the supervisor has a bug and fails to inject an fd, the child’s syscall falls through to Landlock, which denies it. The Landlock floor catches supervisor failures. This is defense in depth: the dynamic layer can only grant access within what the supervisor can open; the static layer ensures the child never exceeds its baseline even if the dynamic layer breaks.
Why Not Other Mechanisms
Why not SECCOMP_USER_NOTIF_FLAG_CONTINUE?
CONTINUE tells the kernel to let the child’s original syscall proceed. For syscalls that take pointer arguments (like openat, which takes a path string), this creates a TOCTOU race: the child can change the path in memory between the supervisor’s check and the kernel’s execution. The child could get the supervisor to approve /tmp/harmless and then swap the pointer to /etc/shadow before the kernel reads it.
fd injection via SECCOMP_IOCTL_NOTIF_ADDFD eliminates this entirely. The supervisor opens the file itself — whatever path it read from the child’s memory is what gets opened. The child’s memory contents after that point are irrelevant.
nono therefore avoids CONTINUE for any path that requires a supervisor authorization decision. The only Linux supervised-mode exceptions are tightly scoped compatibility cases where Landlock is already the enforcement floor:
- Initial allow-list hits outside procfs: if the requested path is already inside the initial capability set, the supervisor can let the child’s original syscall proceed because Landlock will independently enforce the same boundary.
- Missing-path probes (
ENOENT/ENOTDIR): runtimes often probe optional files (/$bunfs/..., loader fallback paths, locale assets). Letting the original syscall continue preserves the kernel’s native “not found” behavior instead of converting those probes into policy denials.
For procfs paths, nono still resolves /proc/self/... in the child context and uses supervisor-opened fds so that procfs symlinks such as /proc/<pid>/fd/* cannot bypass target-path validation.
Why not mount namespaces?
A mount namespace with a minimal filesystem view would eliminate the information leak surface (the child could not stat paths outside the namespace). However:
unshare(CLONE_NEWUSER | CLONE_NEWNS) requires unprivileged user namespaces- Unprivileged user namespaces are disabled by default on Debian, restricted by AppArmor on Ubuntu 23.10+, and turned off in many enterprise configurations
- Building a core security boundary on a mechanism that distro maintainers are actively restricting is fragile
Landlock + seccomp are both available to unprivileged processes on any kernel 5.14+, which covers the vast majority of active Linux installations. A sandbox that requires kernel configuration flags or elevated privileges is a sandbox that gets disabled in practice.
Mount namespaces remain a potential future hardening layer: detect availability at runtime, use them opportunistically when present, fall back to pure Landlock + seccomp when they are not. The security properties of the base architecture remain identical either way.
Why not DYLD interposition on macOS?
Transparent capability expansion on macOS would require intercepting open() calls via DYLD_INSERT_LIBRARIES. This fails for three reasons:
- SIP strips the variable — Apple’s System Integrity Protection removes
DYLD_INSERT_LIBRARIES from Apple Platform Binaries (/usr/bin/env, /bin/bash, /bin/sh). Any command that routes through these interpreters loses the interposition.
- Version manager shims break the chain — Tools like
pyenv and rbenv use shims that exec through SIP-protected interpreters.
- Calling convention mismatch — The variadic
open(const char*, int, ...) function cannot be safely interposed on arm64 without matching the exact register layout, which causes crashes.
macOS supervised mode provides rollback snapshots and diagnostic output, but does not attempt capability expansion. Seatbelt (sandbox_init()) provides the kernel enforcement layer on macOS, with the same irreversibility guarantees as Landlock on Linux.
macOS Claude Code keychain scope
The claude-code profile on macOS grants read-write access to the user keychain root:
It also keeps explicit grants for:
~/Library/Keychains/login.keychain-db~/Library/Keychains/metadata.keychain-db
This is broader than the older “two DB files only” model. In practice, Claude Code’s login and token persistence flow touches more of the user keychain runtime surface than those two files alone, so the narrower grant was not sufficient for reliable auth.
This does not grant the system keychain at /Library/Keychains.
Security implication:
- a process running under the macOS
claude-code profile can interact with the user’s keychain subtree, not just Claude-specific entries
This was chosen as a compatibility tradeoff for the Claude profile. Users who need a tighter boundary should use a custom profile instead of relying on the pack-provided claude-code profile.
For users who want the Claude profile shape without macOS keychain access, nono also provides:
That profile keeps the normal Claude filesystem/runtime allowances but does not relax the macOS keychain deny for ~/Library/Keychains.
The fd Injection Model
When the supervisor approves a request, it does not tell the child “go ahead and open it yourself.” It opens the file and hands the child a file descriptor. This distinction is fundamental to the security model.
What the supervisor does on approval
- Reads the requested path from
/proc/CHILD/mem
- Validates the notification is still live (
SECCOMP_IOCTL_NOTIF_ID_VALID)
- Checks the path against protected nono state roots
- Canonicalizes the path to resolve symlinks
- Re-checks protected roots on the canonical path (a symlink from an innocuous path could point to a protected target)
- Walks the canonical path component-by-component using
openat with O_NOFOLLOW at each step (prevents symlink substitution between canonicalization and open)
- Injects the resulting fd into the child via
SECCOMP_IOCTL_NOTIF_ADDFD with SECCOMP_ADDFD_FLAG_SEND
The SECCOMP_ADDFD_FLAG_SEND flag is critical: it atomically injects the fd and completes the child’s syscall in one operation. The child’s open() returns the injected fd directly.
What the supervisor does NOT do
- Does not pass
O_CREAT — the supervisor cannot be tricked into creating files that do not exist
- Does not pass
O_TRUNC — the child cannot use the supervisor as a proxy to truncate files; it receives a plain writable fd and can seek/write within the file, but truncation is an explicit operation on an fd the user approved
- Does not use
SECCOMP_USER_NOTIF_FLAG_CONTINUE for supervisor-approved paths — authorization decisions still resolve to supervisor-opened fds, not the child’s own openat
Scope of an approved fd
Once injected, the child holds the fd until it closes it. There is no revocation mechanism — this is an inherent property of Unix file descriptors. The approval grants access for the remainder of the session.
Syscall Scope
The seccomp filter traps only openat and openat2. All other syscalls pass through at full speed with zero overhead.
| Syscall | Trapped | Rationale |
|---|
openat / openat2 | Yes | File access is the capability boundary |
read / write / close | No | Hot path; operates on already-granted fds |
stat / access | No | Information leak, but agents handle failures gracefully; not a data exfiltration vector |
unlink / rename | No | Governed by Landlock; cannot affect paths outside the allowed set |
connect / bind | No | Governed by Landlock ABI v4+ network filtering; in proxy mode, restricted to localhost proxy port |
stat and access are not trapped, the sandboxed child can enumerate filesystem structure — file existence, types, permissions — without triggering a supervisor notification. For cooperative agents (the target use case), this is acceptable. For adversarial code, this could enable reconnaissance. The optional mount namespace layer (when available) would close this gap.
Failure Modes
| Failure | Behavior | Safety Property |
|---|
| Supervisor crashes | Notif fd closes; pending syscalls get ENOSYS; child falls back to Landlock | Safe — Landlock denies the access |
| Supervisor denies request | Child receives EPERM | Safe — explicit denial |
| Protected-root match | Request rejected before approval backend is consulted | Safe — protects internal nono state |
| Rate limit exceeded | Request automatically denied | Safe — prevents prompt flooding |
| Child exits during approval | SECCOMP_IOCTL_NOTIF_ID_VALID check fails; supervisor discards the request | Safe — no orphaned state |
| Path canonicalization fails | Supervisor returns error to child | Safe — fail-closed |
Audit Integrity Limits
The audit subsystem has a narrower security claim than the sandbox itself.
- The supervisor is trusted to record events honestly and completely. The sandboxed child cannot write its own audit log, but the audit log still depends on supervisor correctness.
- Session-local hashes are not, by themselves, sufficient history integrity. nono therefore records audited sessions into a global audit ledger as sessions complete.
- The current ledger is still local host state. Without a future signature or external anchor, a host attacker who can rewrite both the session files and the ledger can forge a self-consistent history.
- For supervised sessions, the supervisor hashes the resolved main executable binary and binds that
{ resolved_path, sha256 } identity into session metadata and the global audit ledger.
- When
--audit-sign-key is configured, the supervisor also signs the session’s audit Merkle root and session context using a keyed DSSE/in-toto attestation. The signature is written into the session directory and can later be checked with the corresponding public key.
- That signature is produced once, at session finalization. nono does not sign each individual audit event.
- Command arguments in session metadata and signed audit predicates are best-effort redacted before persistence. The redaction list is intentionally conservative for common flag, header, and URL patterns, but it is not a complete secret detector. User config may add local redaction names; removing defaults requires an explicit unsafe redaction override and is recorded as a policy diff in audit data.
- That executable identity is not full runtime provenance. Shared libraries, interpreter chains, scripts passed as arguments, and dynamically loaded runtime dependencies are not covered by that binary hash.
- The executable hash is computed before
exec, not from the final kernel-loaded file descriptor. A privileged attacker with write access to the executable path could still race between hash and execution.
- The keyed audit attestation is only as strong as the signing key distribution model. If the verifier does not pin the expected public key, a rewritten session could also rewrite the embedded public key and remain self-consistent.
nono audit verify --public-key-file <FILE> is the path that pins verification to an expected signer key. Without that, attestation verification checks the keyed signature against the public key recorded in session metadata.- Filesystem Merkle roots under
--audit-integrity or --rollback commit tracked writable paths, not the full machine state.
The correct way to read the feature today is:
- sandbox enforcement: kernel-enforced and fail-closed
- audit trail: supervisor-recorded and tamper-evident within the local integrity model
- attestation: keyed signing is available for session audit roots, but external anchoring and timestamping are still future work
What If the Supervisor Is Compromised?
A reasonable question: the supervisor can open any file and inject it into the child. If an attacker compromises the supervisor, can they use it as a proxy to feed arbitrary files to the sandboxed agent?
The answer depends on where the attacker is.
From the child (inside the sandbox)
The child cannot compromise the supervisor because the supervisor never runs untrusted code. The agent runs in the child. The supervisor is nono’s own Rust binary — the parent process after fork().
The child’s communication channels to the supervisor are:
- seccomp notification fd — kernel-mediated. The child cannot forge or manipulate these; the kernel generates them from trapped syscalls.
- Unix socket — length-prefixed JSON parsed by serde in memory-safe Rust. Malformed messages are rejected. Valid messages are checked against protected roots, rate-limited, and require user approval.
The child cannot ptrace the parent (blocked by yama ptrace_scope on most distributions, and the child’s own seccomp filter restricts its syscalls). There is no shared memory, no signal-based control channel, and no way to inject code into the supervisor process.
Compromising the supervisor from the child would require a memory corruption bug in nono’s Rust code (memory-safe by default, no unsafe in the IPC path) or a kernel exploit.
From outside (an external attacker)
The supervisor runs as the same user who invoked nono run. It is not setuid, does not run as root, and holds no elevated capabilities. It can only open files the invoking user can already open.
If an external attacker can compromise the supervisor process, they already have user-level code execution on the host. At that point, they can open the same files directly — the supervisor grants them nothing they do not already have. The supervisor is a privilege boundary in the downward direction (restricting the child), not the upward direction.
The supervisor’s external attack surface is minimal:
| Surface | Exposure |
|---|
| IPC socket | Anonymous socketpair() — no filesystem path, no way for external processes to connect |
| seccomp notif fd | Owned solely by the supervisor; no other process holds it |
| Approval input | Reads from /dev/tty; requires access to the user’s terminal session |
| Network | Minimal — in proxy mode, the supervisor listens on a random localhost port protected by a session token; otherwise none |
What if the supervisor has a vulnerability?
Even in an unprivileged supervisor, a memory corruption vulnerability could allow the child to escape the sandbox by hijacking the supervisor’s control flow. The question is how realistic this is.
Rust eliminates the most common vulnerability classes. Buffer overflows, use-after-free, double-free, and format string attacks are structurally impossible in safe Rust. The compiler prevents them, not programmer discipline. The IPC message parsing uses serde JSON with no manual buffer management — there is no sprintf into a stack buffer, no memcpy with an attacker-controlled length.
The unsafe surface is small and does not parse complex input. The unsafe blocks in the supervisor path are limited to libc FFI calls: openat, poll, seccomp ioctls, and SCM_RIGHTS fd passing. These are thin wrappers around syscalls with fixed-size arguments, not parsing routines operating on attacker-controlled data.
The child can only deliver a payload through two narrow channels:
| Channel | Data Format | Parser |
|---|
| Unix socket | Length-prefixed JSON | serde (memory-safe, widely audited) |
/proc/CHILD/mem | Bounded-length path string | canonicalize + openat (standard libc) |
unsafe FFI block with a delivery mechanism from the child, they achieve user-level code execution in the supervisor. This is the same privilege level the invoking user already has — the attacker has escaped the sandbox but has not escalated privileges. This is meaningful (a sandbox escape is a real security event) but it is not the catastrophic outcome of compromising a root-level supervisor.
The risk is not zero — nothing is. But Rust’s memory safety guarantees make the traditional exploit classes structurally impossible across the vast majority of the codebase, the remaining unsafe surface is small and constrained, and the worst-case outcome is lateral movement to the user’s own privilege level rather than privilege escalation.
The key distinction
The supervisor is not a privilege escalation target because it does not hold privileges the user does not already have. This is a deliberate design choice. nono runs entirely unprivileged — no root, no CAP_SYS_ADMIN, no setuid. An architecture where the supervisor ran with elevated privileges (as some container runtimes do) would make supervisor compromise a serious escalation vector. nono avoids this by design.
Network Proxy Security Model
When --network-profile or --allow-domain is used, nono starts an HTTP proxy in the supervisor process and restricts the child to ProxyOnly mode — only localhost:<port> is reachable from inside the sandbox.
Enforcement Layers
| Platform | Mechanism | What It Restricts |
|---|
| Linux | Landlock ABI v4+ per-port TCP rules | connect() limited to proxy port only |
| macOS | Seatbelt (allow network-outbound (remote tcp "localhost:PORT")) | All other outbound denied |
connect() to any address other than 127.0.0.1:<port> returns EPERM.
Session Token Authentication
Every proxy session generates a 256-bit random token (via getrandom). The child receives it as NONO_PROXY_TOKEN. Every request must include this token:
- CONNECT mode:
Proxy-Authorization: Bearer <token>
- Reverse proxy mode:
X-Nono-Token: <token>
Tokens are compared using constant-time equality to prevent timing attacks. This prevents other localhost processes from using the proxy even if they discover the port number.
DNS Rebinding Protection
The proxy resolves DNS itself and checks all resolved IP addresses against the link-local range before connecting. This prevents attacks where:
- An attacker controls DNS for an allowed hostname
- DNS returns a link-local address (e.g.,
169.254.169.254)
- The proxy would connect to the cloud metadata service thinking it’s an allowed external API
Link-local IPs (169.254.0.0/16, fe80::/10) are always blocked after DNS resolution. Cloud metadata hostnames are also hardcoded as denied. Private network addresses (RFC1918) are allowed to support enterprise environments.
Credential Isolation
In reverse proxy mode, API credentials are loaded from the system keyring at proxy startup and stored in the supervisor’s memory as Zeroizing<String>. They are never passed to the sandboxed child:
- The child sees
OPENAI_BASE_URL=http://127.0.0.1:<port>/openai — a local HTTP URL with no key
- The proxy injects
Authorization: Bearer sk-... when forwarding to the upstream over TLS
- The child cannot read the credential from the proxy’s memory (separate process, no shared memory, no
ptrace)
If the child’s traffic is captured (e.g., by a rogue library logging HTTP requests), only the local proxy URL is visible. The real API key never appears in the child’s address space.
Proxy Failure Modes
| Failure | Behavior | Safety Property |
|---|
| Proxy crashes | Child loses all network access (only proxy port was allowed) | Safe — fail-closed |
| Invalid token | Proxy returns 403 | Safe — authentication enforced |
| Host not in allowlist | Proxy returns 403 | Safe — deny by default |
| DNS resolves to denied CIDR | Proxy returns 403 | Safe — rebinding protection |
| Upstream TLS failure | Proxy returns 502 | Safe — no fallback to plaintext |
Audit Durability Boundary
Network proxy events are captured during the session, but the durable append-only audit log is finalized after the session ends rather than updated on every proxied request.
This is an intentional performance tradeoff: the live request path only pays the cost of lightweight event capture, while the append-only hash chain and Merkleized audit summary are written during session finalization. The result is good post-run audit integrity, but not per-request durability.
The security implication is narrow but real: if the supervisor or proxy is forcibly terminated mid-session, recent network events may be lost before they are committed into the append-only audit record. This does not weaken sandbox enforcement or credential isolation, but it does leave a temporary gap in forensic durability. Tightening that window is future work.
macOS Model
On macOS, Seatbelt provides the kernel enforcement layer via sandbox_init(). The security properties are equivalent to Landlock:
- Irreversible once applied
- Enforced by the XNU kernel
- Inherited by child processes
- No userspace escape mechanism
Supervised mode on macOS provides rollback snapshots (content-addressable filesystem snapshots for restoring pre-session state) and the diagnostic footer, but does not provide capability expansion. The Seatbelt sandbox is the single enforcement layer.
Isolation Scope and Deployment Model
nono provides fine-grained, kernel-enforced capability control, but it is not a monolithic isolation stack. Understanding this distinction matters when deciding how to set policy and deploy nono.
What nono is
nono is a capability-based sandbox that provides fine-grained isolation controls and operates at the OS syscall level. It uses Landlock on Linux and Seatbelt on macOS. It gives precise, per-path, per-domain, per-socket, per-env-var, per-operation control over what a process can touch and see. It’s designed for the nuances of an agent acting within its operating context—something not practical or even possible with a microVM or container.
What nono is not
nono is not Firecracker, not a hypervisor, and not a container runtime. It does not provide a separate kernel boundary, hardware-level memory isolation, or full filesystem namespace separation. The sandboxed process shares the host kernel with everything else running on the machine.
This has a direct practical implication: nono’s effectiveness is proportional to the accuracy of the policy applied to the environment it runs in. Operating systems and Linux distributions vary significantly in their default filesystem layouts. Package managers, init systems, and service daemons leave files in locations that differ between distributions, and /run is a clear example, where contents and structure can vary widely. nono ships with sensible defaults for common layouts, but no default set can anticipate every variation, and an incorrectly scoped policy can leave gaps.
This is not a weakness unique to nono. SELinux, AppArmor, and seccomp profiles all require tuning to the environment and face the same problem. The difference is that nono makes policy explicit and declarative.
nono can act as a complete isolation layer when its policy is correctly tuned to the environment it runs in. It is not a turnkey solution that works identically out of the box across every distribution and service configuration, it is a primitive that rewards correct configuration.
Combining nono with hardware isolation
For deployments that require the strongest possible guarantees, nono composes cleanly with existing isolation layers. Running nono inside a container or microVM gives you both layers simultaneously:
- The hardware-level boundary, kernel isolation, and namespace separation of the container or VM
- The fine-grained per-path, per-operation capability control of nono inside that boundary
Neither layer replaces the other. A microVM or container without nono cannot restrict an agent to specific files within a mounted directory, short of managing potentially hundreds of volume mounts, an approach that becomes operationally unworkable at any real scale. nono without a microVM trusts the host kernel and the host filesystem layout is aligned with the policy.
| Deployment | Perimeter | Granularity |
|---|
| nono alone | Host kernel (Landlock / Seatbelt) | Per-path, per-operation |
| Container alone | Namespace + cgroup boundary | Coarse (mount, network namespace) |
| microVM alone | Hardware VMM boundary | Coarse (virtual device, network) |
| nono inside container or microVM | Hardware VMM + kernel enforcement | Per-path, per-operation within the VM boundary |
Summary
The architecture optimizes for three properties simultaneously:
- Unprivileged deployment — no root, no
CAP_SYS_ADMIN, no kernel configuration changes. Works on any kernel 5.14+ out of the box.
- Defense in depth — Landlock provides a hard floor that catches failures in the dynamic layer. The supervisor can only grant what it can open. Protected-root checks ensure internal nono state remains off-limits to dynamic grants.
- Transparency — the sandboxed agent does not need to know about nono. Standard
open() calls succeed after supervisor approval. No retries, no special APIs, no agent modifications.
The result is a sandbox that is both strong (kernel-enforced, irreversible, fail-closed) and usable (agents work unmodified, users approve access interactively, the hot path has zero overhead).